科研项目
带隐私保护的异步多模态线索语自动识别研究
鉴于听力障碍人群在全球的广泛分布以及Cued Speech(CS)来越普遍的应用,为了使聋哑人的沟通更加便利和高效,本项目拟开发一个基于人工智能的CS视频到文本的自动识别模型(见图1),以期促进CS自动识别的研究成果真正走向应用,造福于聋哑人士以及更多有需要的人。
影响力:对于本项目拟建立的基于人工智能的CS自动识别模型,它的落地应用将很好地帮助聋哑人和有听力障碍的人群之间的交流,服务于聋哑人士。这也将助力于《中华“十三五”加快残疾人小康进程规划纲要》中明确提出的“改善残疾人民生,加快残疾人小康进程”的目标。
挑战:带噪标注与数据分布不平衡下的CS多模态特征表征能力受限;2) CS异步多模态对齐与融合效果不佳; 3)缺乏带数据隐私保护的CS自动识别模型。
1.针对数据集的长尾分布问题,在模型层面上解决此问题,将会大大地减少工业界收集无偏数据集的成本,提高模型性能。本项目拟提出的基于元学习的双层优化重加权方法可以被后续扩展到其他有带噪标注和数据有偏分布的问题中,具有很好的延续性和潜在的影响力。
2.多模态数据也是当今研究的一大热点,随着数据模态的增加,恰当地利用他们之间的互补关系,进行协同学习,可以很大程度地提高模型的性能。本项目拟对CS视频异步信息的精细对齐以及对抗生成融合模型的顺序优化进行深入研究。该模型引入的新思路将为多模态融合打开一个新的视角,并且先初对齐再融合的顺序优化机制也对揭示异步融合这个难题的内在机理有很好的启发意义。
3.本项目拟建立的基于联邦学习的视听识别整体模型将首次考虑到保护CS编码者隐私的问题,构建基于安全混合算法的样本插值来生成共享数据集参与训练的方法,并将其应用于联邦学习框架下的CS自动识别模型的训练。该研究将为目前人工智能模型在隐私保护方面的探索提供宝贵的思路。
四、社会经济效益以及产业前景
根据调研,很多聋哑人康复中心,聋哑学校以及有聋哑人的家庭对本项目提出的技术产业化非常期待。同时,申请人与多家公司交流后发现,他们也对此项目可能的产业化合作十分感兴趣。此项目的研究成果可以运用于移动电子设备(如手机),以方便有需要的人士进行日常交流。另外,也可以用于制作成上课软件,用于聋哑学校的课堂授课。除此之外,拟研发的产品可以使得儿童能轻松地阅读大量的课外书籍, 和正常同龄人一起参加课外活动等,这将大大丰富他们的日常生活。为更好地评估本项目产业化贡献,本项目拟在后期进行初步的软件开发以及试用。然后设计匿名问卷调查,来评估本项目产业化成果,这也可以加快本项目的产业化进程,并且减少走不必要的弯路。
本项目的研究对于唇读、听力障碍者早期教育、语音纠正和治疗、机器人、视听转换以及与人机互动等领域也具有重要的促进作用。因此,本项目的研究成果也可以用于这些领域的智能应用,促进相关产业化发展进程。
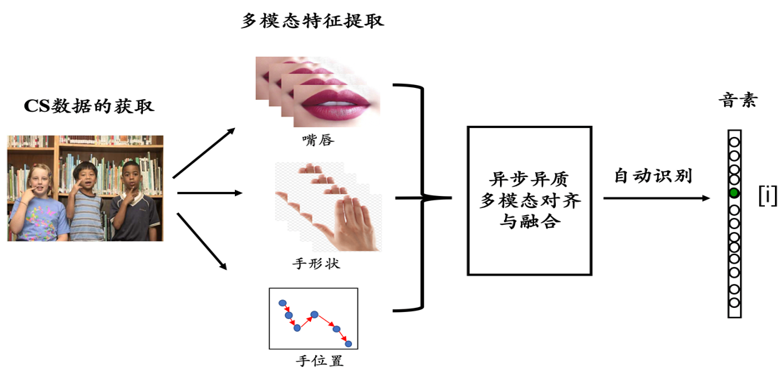
图1. CS视频到文本自动识别的整体框架
五、合作伙伴
法国格勒诺布尔Gipsa-Lab的冯钢教授
英国University of Surrey的王文武教授


