Projects
Hierarchical Understanding of Visual Content based on Cross-Modality Image-Text Feature Joint Representation
Project description/goals
The hierarchical understanding of visual contents is intended to comprehensively analyze different levels of visual information, such as the objects in the image scene, the attributes of the objects, and the interaction between the objects. However, to solve this task in a supervised manner requires fine-grained annotation, making data-hungry deep learning approaches elusive. This project will discuss how to optimize the model with a huge number of image-text pairs on the Internet, so as to achieve fine-grained and hierarchical understanding for visual contents.
Importance/impact, challenges/pain points
We aim to solve the deficiencies of existing solutions in the aspects of data collection, model design, learning strategies, etc. To begin with, make full use of the correlation of online image data and its corresponding textual descriptions. In the meantime, consider adding following aspects into the modeling process: (1) the internal relationship between different levels of semantics (2) the relevance, as well as consistency, between these relationships and different levels of visual representation. This project is expected to empower the model to automatically mine the hidden information in the massive multi-modality data and improve the generalization ability of the model.
Solution description
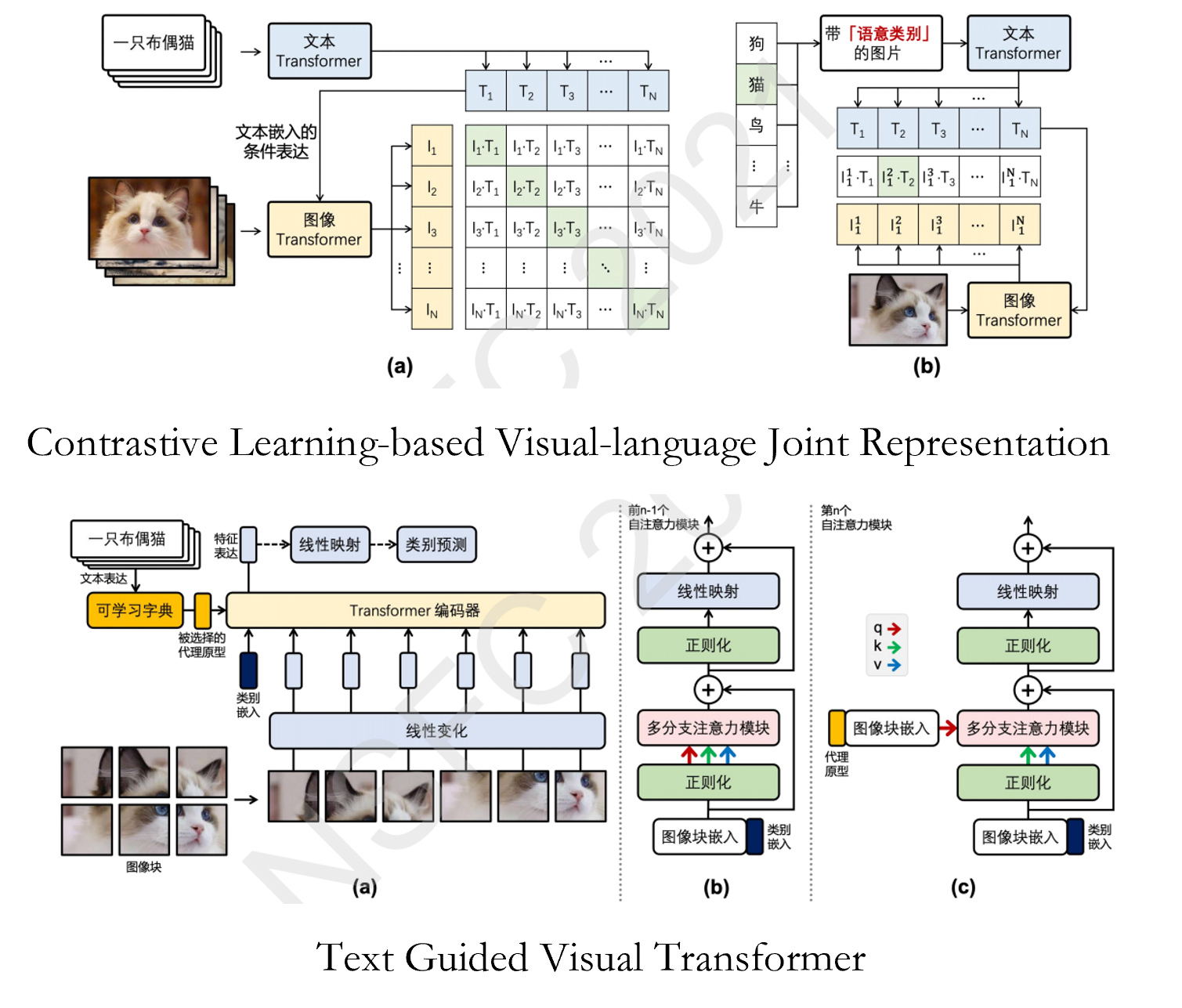
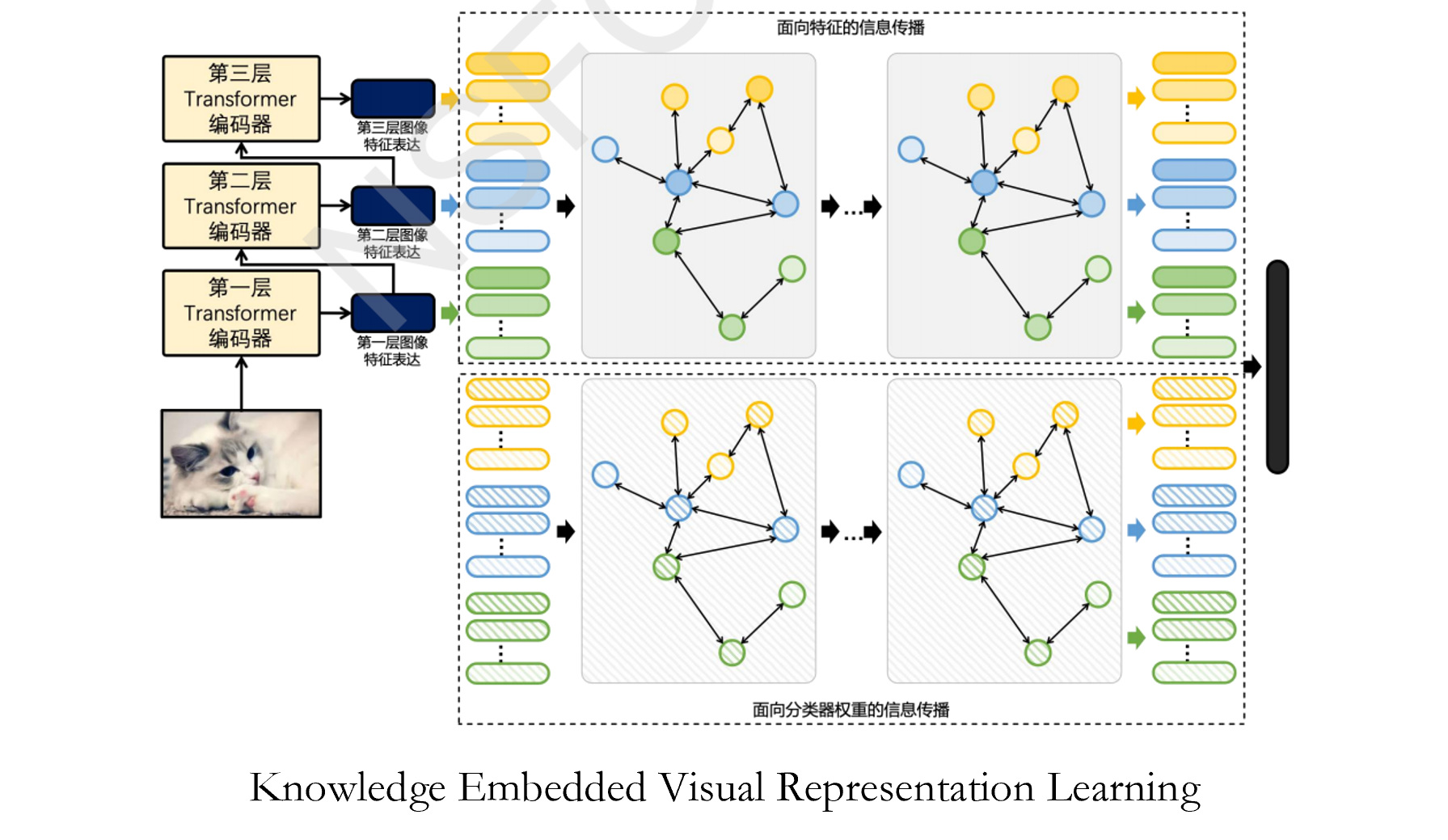
1. Propose a contrastive-learning based framework for image-text joint representation learning. 2. Design a hierarchical deep visual model for unified learning of object attributes, categories, interactions, etc. 3. Introduce knowledge graphs to realize joint learning driven by knowledge and vision-language data.

Key contribution/commercial implication
This project will (1) exploit Internet image and text resources further efficiently, (2) design the network architecture, (3) explore the image-text corresponding relationship in the learning process, and (4) improve the representation ability and the performance of the model.
 Next steps
Next steps
So far, this work is mainly focused on the construction of the framework for image-text joint representation learning, and the design of model to effectively perceive multiple levels of semantic content. Related technologies will also promote medical image analysis and medical report generation.
Team
Zhang Ruimao.


