Projects
Coding-based distributed big data processing theory
Project description/goals
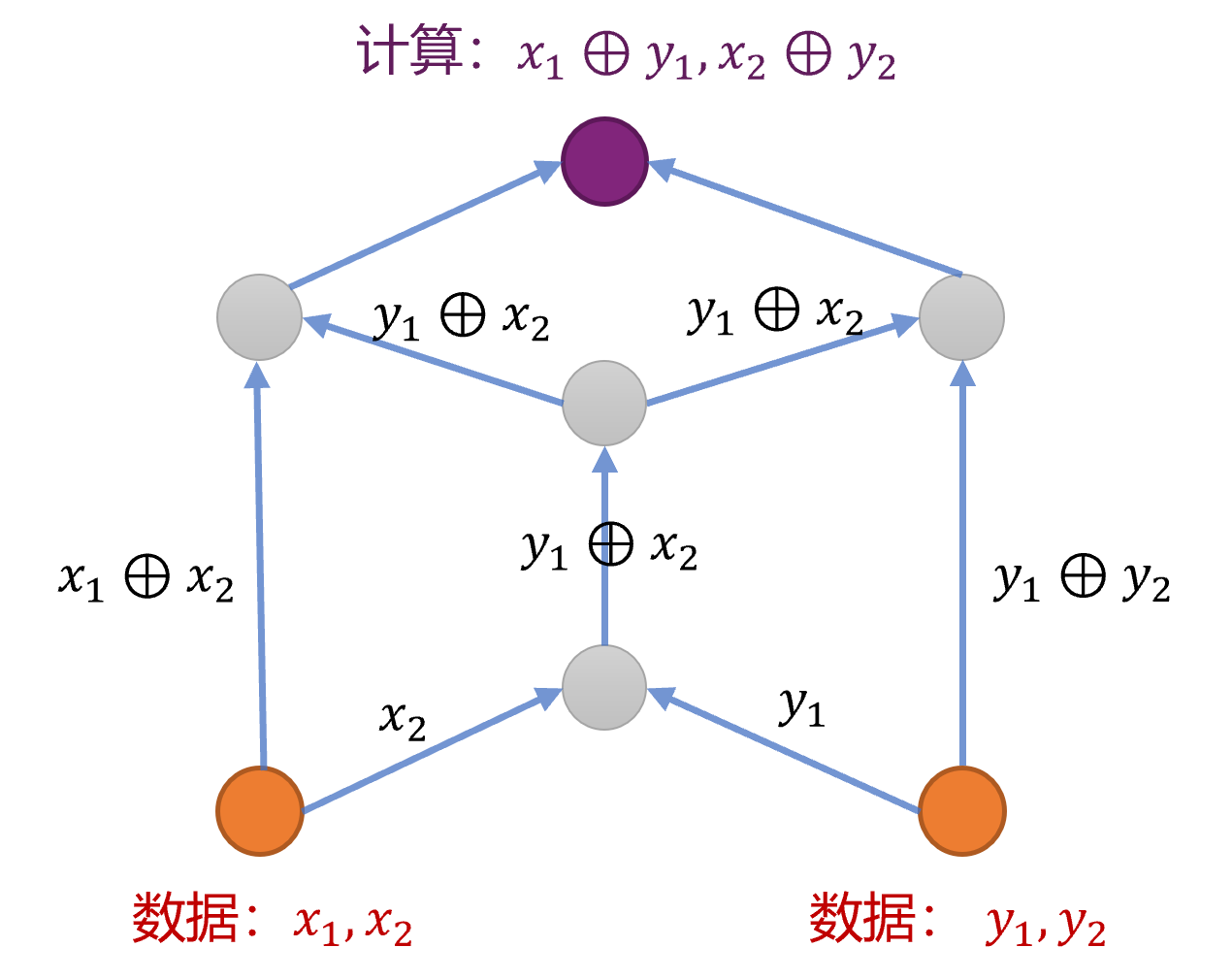
The research adopts a new idea to improve network computing power: that is, to solve multiple different problems jointly through the method of network calculation and coding, thereby increasing the network bandwidth.
Importance/impact, challenges/pain points
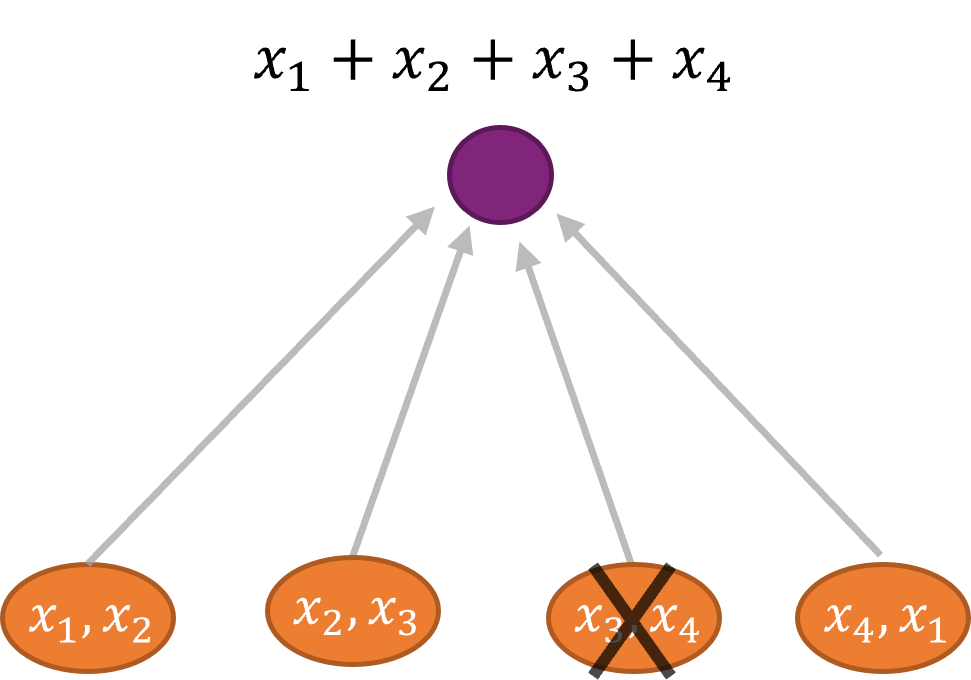
Through the implementation of this project, a number of coding methods for distributed data processing are proposed. These methods can be applied to various types of data collection and processing systems including data centers and edge computing platforms to improve the reliability of data processing. , And improve network bandwidth efficiency.
Challenges/pain points: There are many incompatibility between the coding-based method and the existing system design concept, which leads to a long-term accumulation of the method before it can be used in reality.
Solution description
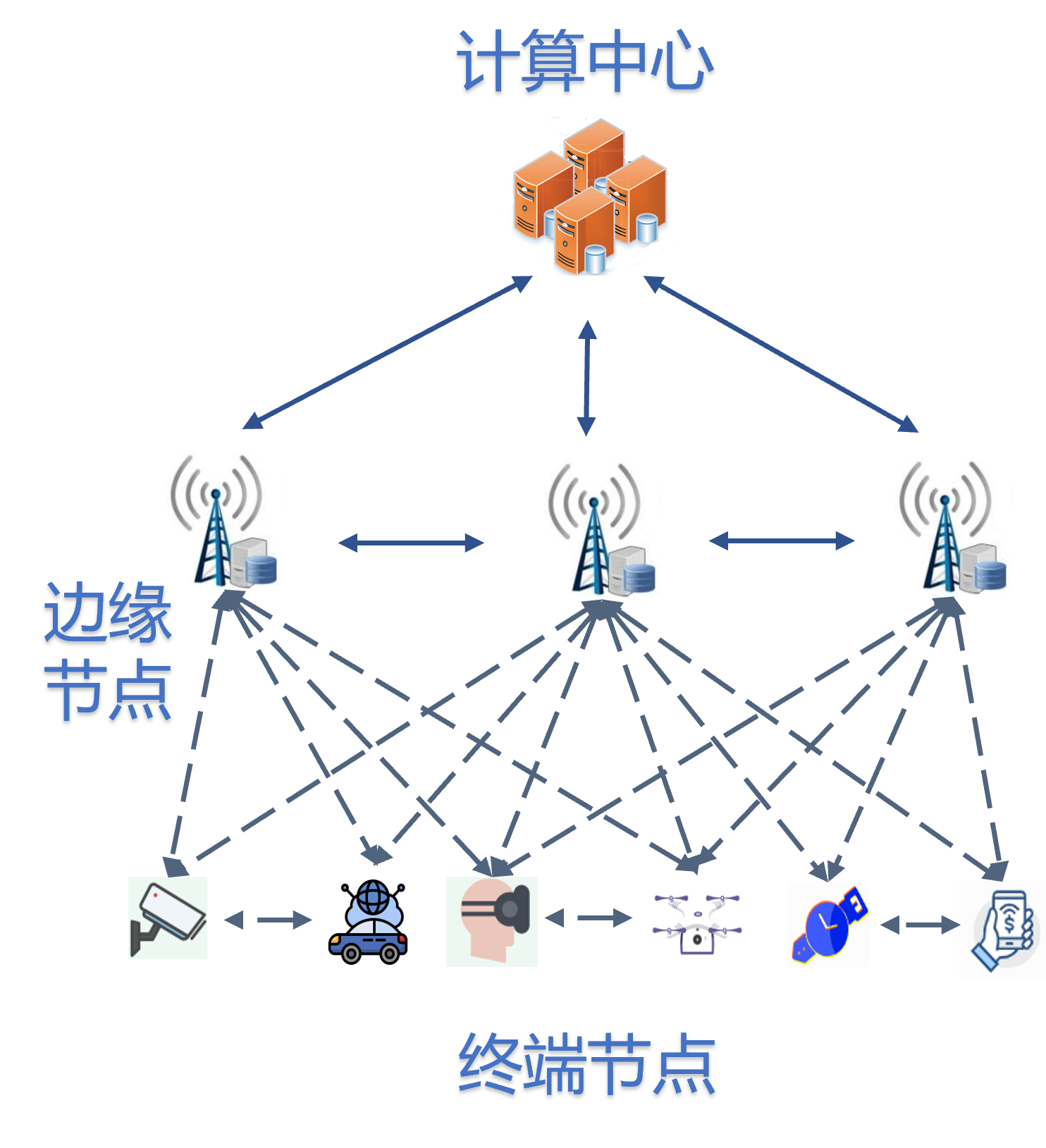
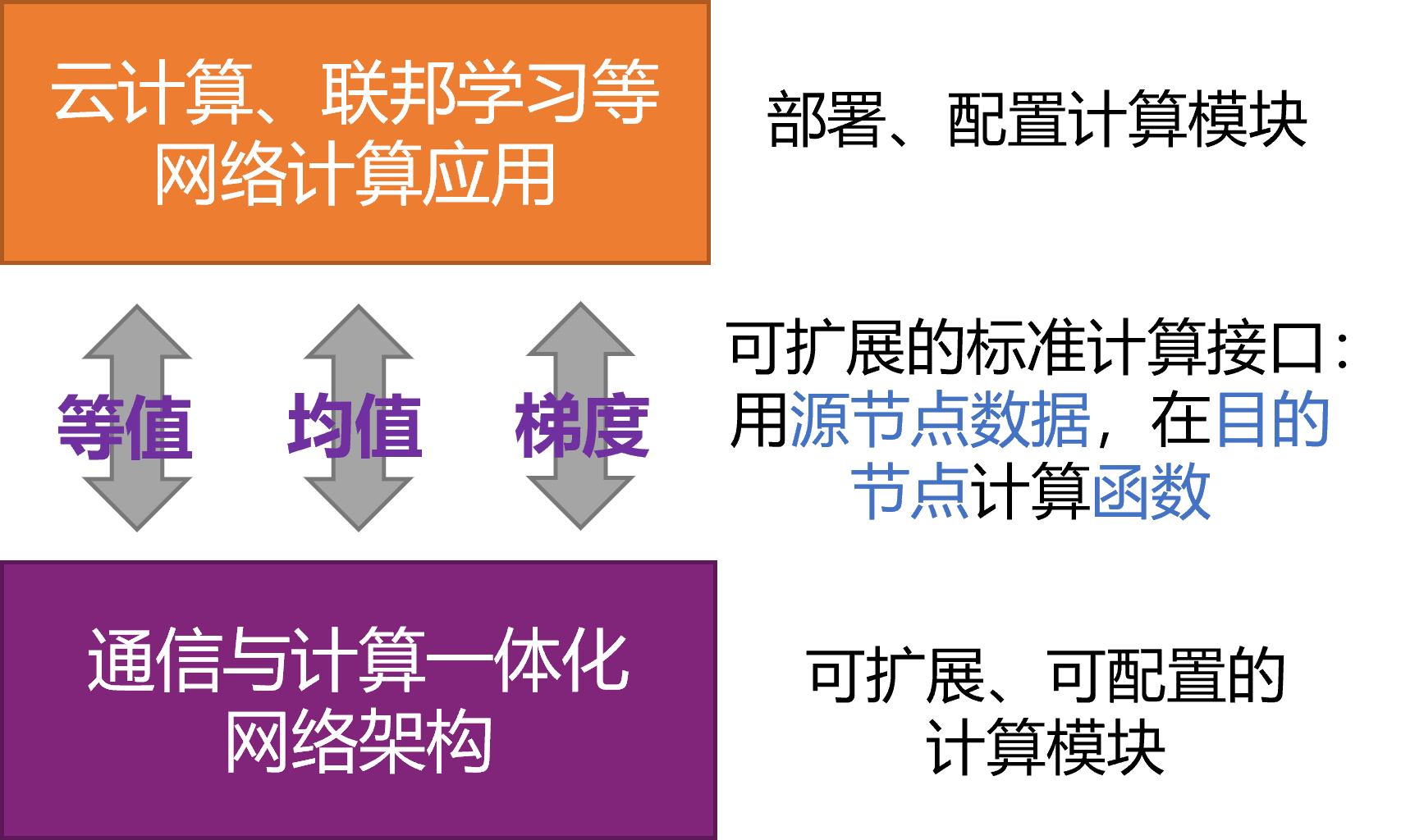
Cooperate with companies to build a complete set of coding-based network computing (cloud) platforms from the ground up. From the underlying storage architecture to the optimized architecture of network computing, all are redesigned and implemented based on coding theories and technologies.
Key contribution/commercial implication
Coding-based network computing theory and technology has shown great value in many aspects, and it is a key technology to achieve breakthroughs in future distributed big data computing methods.
Next steps
Cooperate with companies to build a complete set of coding-based network computing (cloud) platforms from the ground up.
The project team was recently funded by the National Natural Science Foundation of China to study information theory integrating communication and computing.
Collaborators/partners
The Chinese University of Hong Kong, Shenzhen
Team/contributors
Prof. Yang Shenghao


