Projects
Automatic Recognition of Asynchronous Multimodal Cued Speech with Privacy Protection
Project description/goals
As 6G wireless networks are shifting to the new paradigm of global coverage, all spectra, and full applications, efficient radio resource management becomes the key to release the potential of 6G systems. Nevertheless, the large-scale radio Introduction/Objectives.
In view of the wide distribution of deaf people in the world and the increasing application of Cued Speech (CS), to make the communication of deaf-maimed people more convenient and efficient, this project plans to develop an AI-based CS video-to-text automatic recognition model (see Figure 1). It can promote the real application of the research results of the CS automatic recognition, and benefit the hearing-impaired and more people in need.
Impact/Challenge
Impact:
The application of AI-based CS automatic recognition model proposed in this project will help the communication between deaf or hard-of-hearing people, and serve them. This will also contribute to the goal of "improving the livelihood of persons with disabilities and speeding up the prosperity for persons with disabilities" clearly stated in “Outline for Accelerating the Process Toward Prosperity for Persons with Disabilities in the 13th Five-year Plan Period”.
Challenge:
1) CS multimodal feature characterization capability is limited with noisy label and imbalanced data; 2) Alignment and fusion of CS asynchronous multimodal are not good; 3) Lack of CS automatic recognition model with data privacy protection.
Solutions/Contributions
Solving the long-tail datasets problem at model level will greatly reduce the cost of collecting balance datasets and improve the performance of model. The proposed bi-level optimization reweighting method based on meta-learning can be extended to other problems with noisy label and biased data distribution, which has good continuity and potential influence.
Multimodal data is also a hot topic in the current research. With the increase of data modalities, the performance of the model can be greatly improved by properly utilizing the complementary relationship among them for collaborative learning. This project intends to conduct in-depth research on fine alignment of CS video asynchronous information and sequence optimization of adversarial generation fusion model. The new idea introduced by this model will open a new perspective for multi-modal fusion, and the sequential optimization mechanism of the first alignment and then the fusion is also instructive to reveal the intrinsic mechanism of asynchronous fusion.
The audio-visual recognition model based on federated learning proposed in this project will consider the protection of CS coders‘ privacy for the first time. It uses security hybrid algorithm to generate shared dataset for the model training.
Social and economic benefits and industrial prospects.
According to the research, many deaf rehabilitation centers, deaf schools and families with deaf people are looking forward to the industrialization of the technology proposed in this project. At the same time, several companies are also very interested in the possible industrialization cooperation of the project. In addition, it can also be made as a teaching software for deaf schools. Besides, the products to be developed can make children easily read a large number of extracurricular books, and participate in extracurricular activities with the normal hearings, which will greatly enrich their daily life. In order to better evaluate the industrialization contribution of the project, the project plans to carry out preliminary software development and trial in the later stage. Then, an anonymous questionnaire is designed to evaluate the industrialization results of the project, which can also speed up the industrialization process of the project and reduce unnecessary troubles.
This project also has an important role in promoting lip-reading, early education of hearing impairment, speech correction and treatment, robotics, audio-visual conversion and human-computer interaction. Therefore, the research results of this project can also be used for intelligent applications in these fields to promote the relevant industrialization development process.
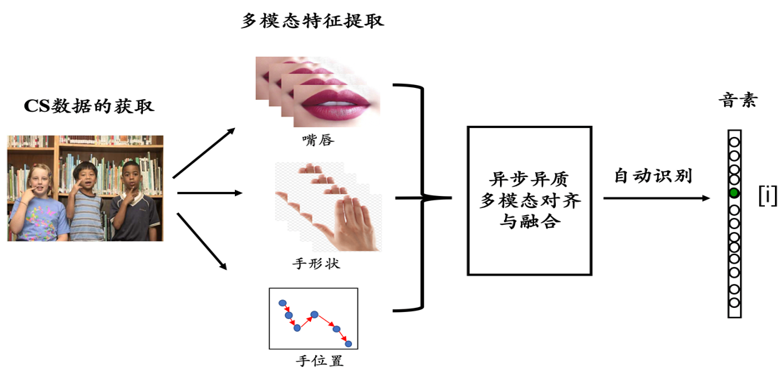
Figure 1. The framework of CS video to text automatic recognition
Cooperator
Prof. Gang Feng, GIPSA-Lab in Grenoble, France.
Prof. Wang Wenwu, the University of Surrey, UK.
Team
Liu Li.


